
Pytorch Dropout에 대하여
모두를 위한 딥러닝 - 파이토치 강의 참고
Dropout은 모델의 layer가 많아질때 생기는 overfitting문제를 해결하기 위해 사용된다.
overfitting이란 train데이터를 모델이 지나치게 정확히 학습하는 바람에 모델이 test데이터에서는 좋은 결과를 내놓지 못하는 경우이다.

위 그림에서 초록색선을 보면 빨간점과 파란점을 완벽하게 분류하는 것을 확인할 수 있다. 이렇게 train 데이터에 지나치게 학습된 경우를 overfitting이라하며, 적절한 학습의 정도를 까만선이 나타내고 있다.
이러한 overfitting문제를 해결하기 위해 dropout을 사용하게 된다.
dropout이란 forward함수를 통해 train데이터가 layer를 지날때 뉴런 일부를 생략하고 학습을 진행하는것이다.
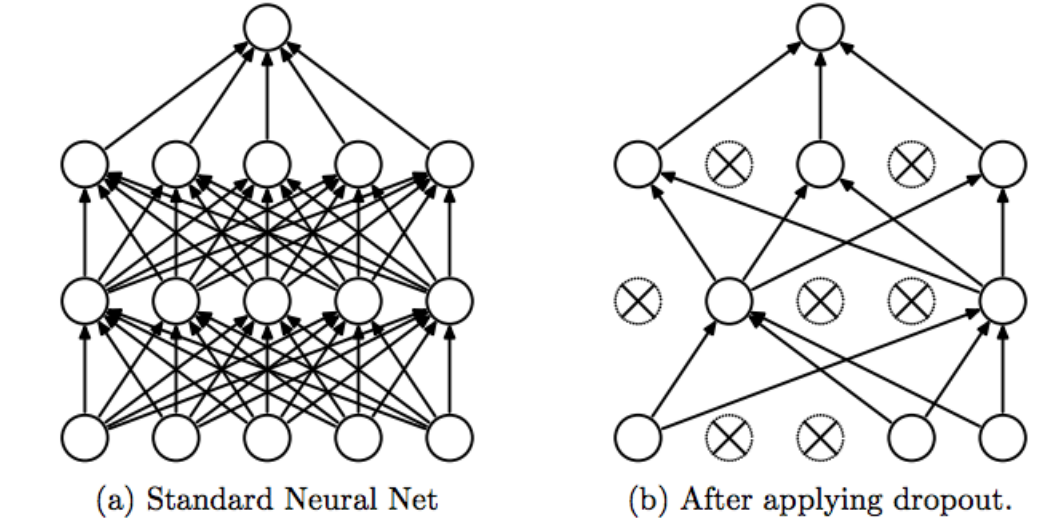
위의 우측 그림과 같이 layer마다 임의의 뉴런을 생략하고 학습을 진행하는 것을 볼 수 있다.
사용자가 정의한 비율만큼의 뉴런을 생략하고 학습을 진행할 때, 매 epoch마다 다른 뉴런들이 꺼졌다가 켜지기를 반복하게 된다.
이는 매번 다른 모델을 학습하는것과 유사하기 때문에 Ensemble(앙상블)효과를 기대할 수도 있다.
dropout을 사용할 때는 non-linear 활성화 함수 다음에 사용하게 된다.
MNIST 데이터셋을 이용해 활용법을 살펴보자.
통과할 linear 와 relu 그리고 dropout을 설정해준다.
1 | # nn Linear layer / relu / dropout 만들기 |
- 이를 이용해 모델을 만들때 선형함수를 통과하고 활성화 함수를 지난 뒤에 dropout을 적용해준다.
1 | model = torch.nn.Sequential(linear1, relu, dropout, linear2, relu, dropout, |
이렇게 만들어진 모델로 학습과 평가를 똑같이 진행할 수 없다.
왜냐하면 학습 이후 평가할 때 dropout이 켜져있다면 모든 weight를 사용하지 않고 output을 내게 되기 때문이다.
이렇게 dropout은 학습할때는 사용하고, 평가를 위해서는 사용하지 말아야한다.
이를 조절할 수 있는 함수가
train()함수와eval()함수이다.다음고 같이
train()함수를 통해 dropout을 사용하겠다는 표시를 한 후, 학습을 진행해야 한다.
1 | model.train() # train() 함수를 사용하면 dropout=True로 설정된다. |
- 학습을 마친 후, 랜덤한 하나의 데이터를 통해 결과를 확인해 보고 싶다면 다음과 같이
eval()함수를 통해 dropout을 사용하지 않겠다고 표시한 후 평가를 진행해야 한다.
1 | with torch.no_grad(): # --> 여기에서는(test에서는) gradient를 계산하지 않고 진행한다는 뜻이다. |
첫째로, dropout은 non-linear 활성화 함수 다음에 사용한다는 점
둘째로, 학습과 평가를 위해서는
train()함수와eval()함수를 반드시 사용해야 된다는 것을 기억해야겠다.