
Pytorch Batch Normalization에 대하여
모두를 위한 딥러닝 - 파이토치 강의 참고
overfitting과 gradient vanishing문제를 해결하기 위해 앞서서 ReLU 포스트와 Dropout 포스트를 적었었다.
이번 포스트에서는 또 다른 방법인 Batch Normalization방법을 정리하고자 한다.
Batch Normalization은 모델이 깊어질수록 나타나는 Internal Covariate Shift를 해결하면서 등장했다.
Internal Covariate Shift란 모델이 깊어질수록 output의 분포가 편향되는 문제를 말합니다.
이를 해결하기 위해 Batch마다 output을 Normalization하는 방식이 등장합니다.
Batch Normalization도 dropout과 똑같이
train()과eval()을 구분지어서 사용해야 합니다.왜냐하면, Batch Normalization을 통해
평균, 분산과 학습하는 데이터scale값 감마, shift값 베타를 저장해서 사용하기 때문입니다.따라서, 학습을 위해서는 dropout때와 마찬가지로
train()함수를, 평가를 위해서는 저장된 값을 이용하기 위해eval()함수를 먼저 작성해야합니다.Batch Normalization은 dropout과 다르게 활성화 함수 이전에 적용시킵니다.
이를 이용해 Batch Normalization을 사용한 경우와, 사용하지 않은 경우를 비교해 보겠습니다.
Dropout 포스트때와 유사하지만 Batch Normalization을 다음과 같이 만들어서 두 가지 모델을 정의했습니다.
1 | linear1 = torch.nn.Linear(784, 32, bias=True) |
- 이후, 학습을 진행할 때 각 epoch마다 평가를 진행하면서 Loss와 Accuracy를 저장시켜 line plot을 그려 비교해 보겠습니다.
1 | # 학습 & 각epoch 마다 평가 |
이후 train과 validation의 Loss와 Accuracy를 Line Plot으로 그려 확인할 수 있었습니다.
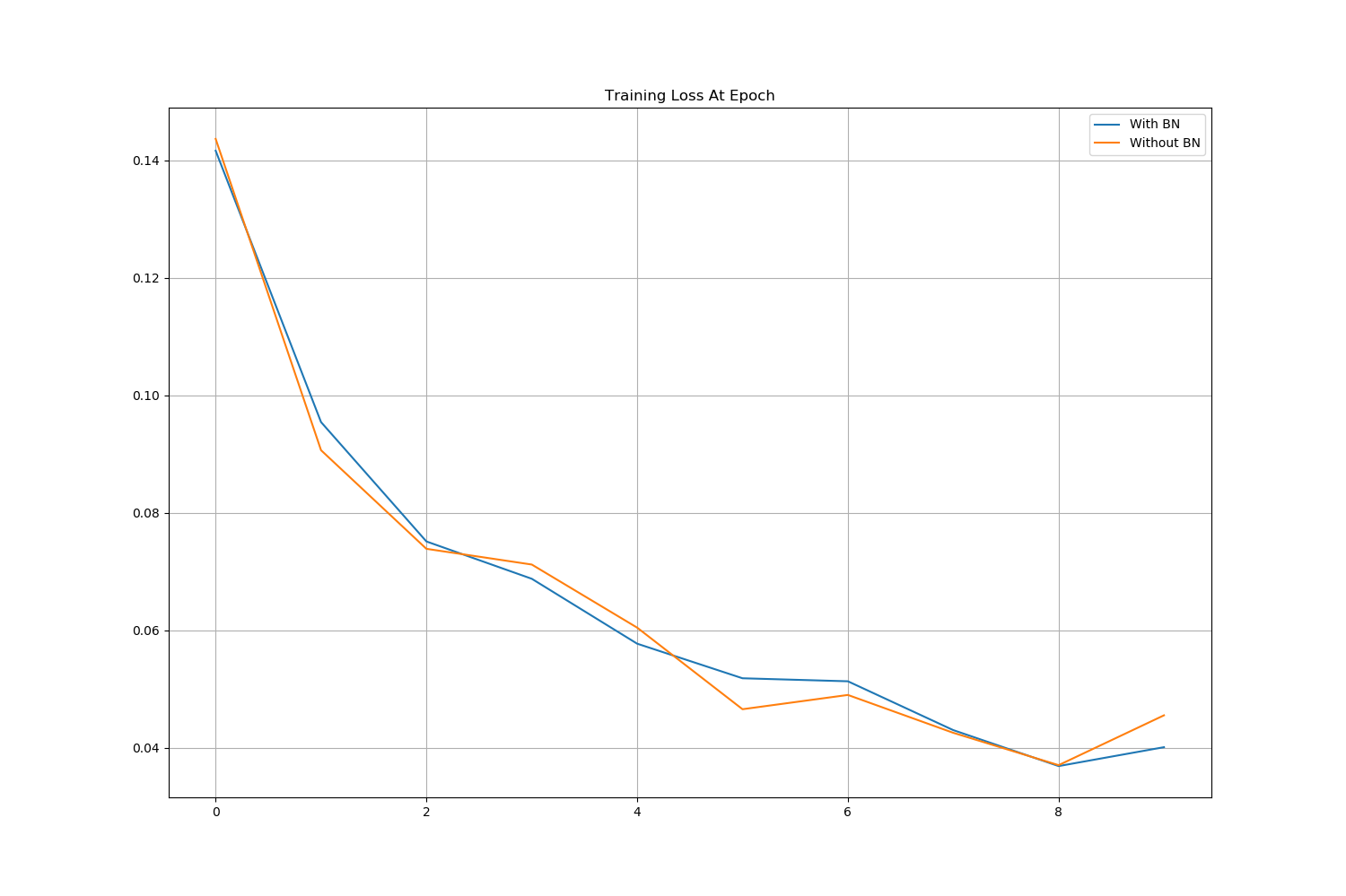
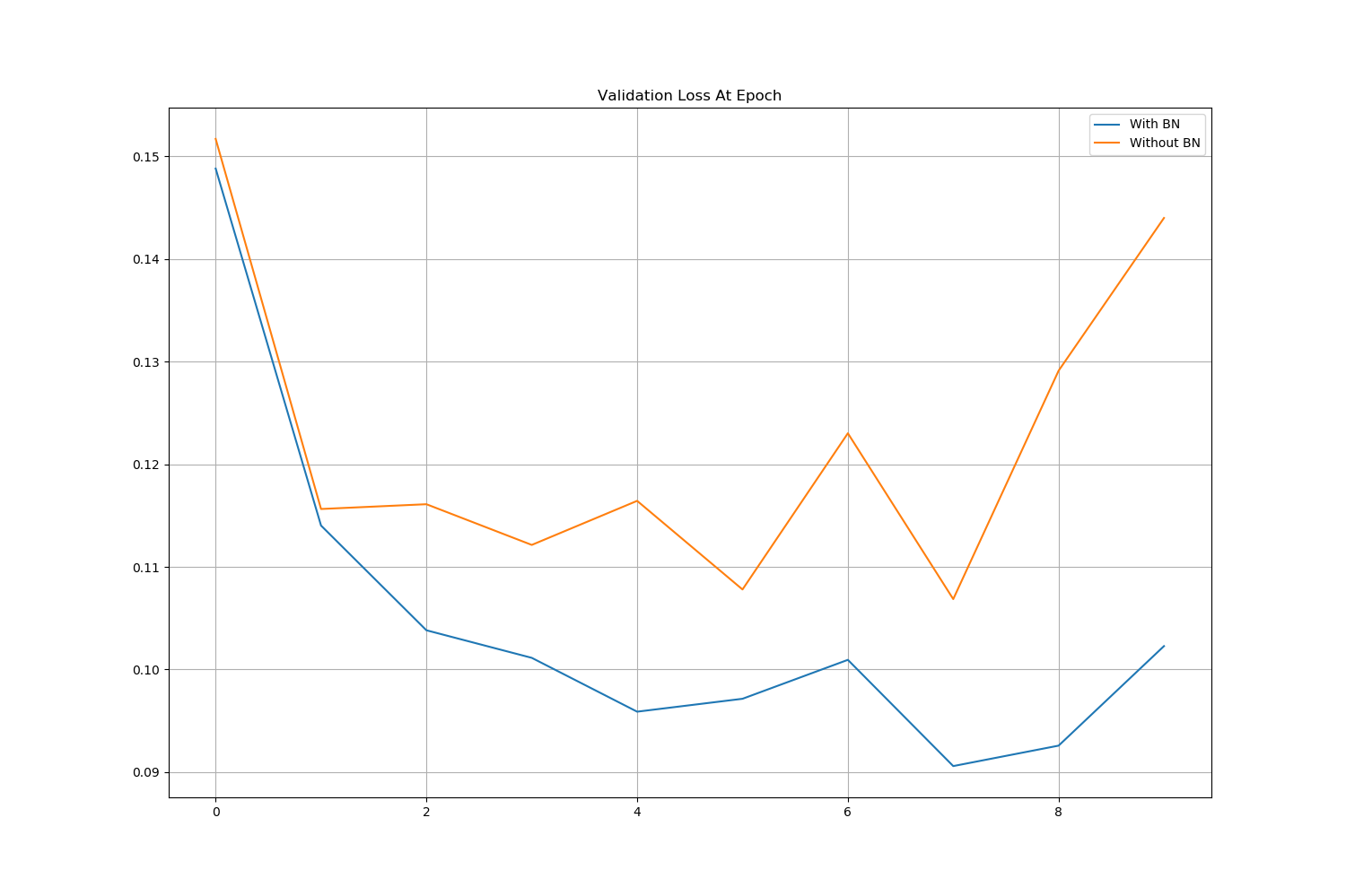

그림에서도 확인할 수 있듯이 Batch Normalization을 적용했을 때, validation의 Loss가 더 작은것을 확인할 수 있었습니다.
데이터 로딩 ~ 이미지 생성까지 생략된 부분은 아래 Full Code를 확인해주세요.